训练集、测试集、交叉验证
通常,在训练有监督的机器学习模型的时候,会将数据划分为训练集、验证集合测试集,划分比例一般为0.6:0.2:0.2。对原始数据进行二到三个集合的划分,是为了能够选出效果(可以理解为准确率)最好的、泛化能力最佳的模型。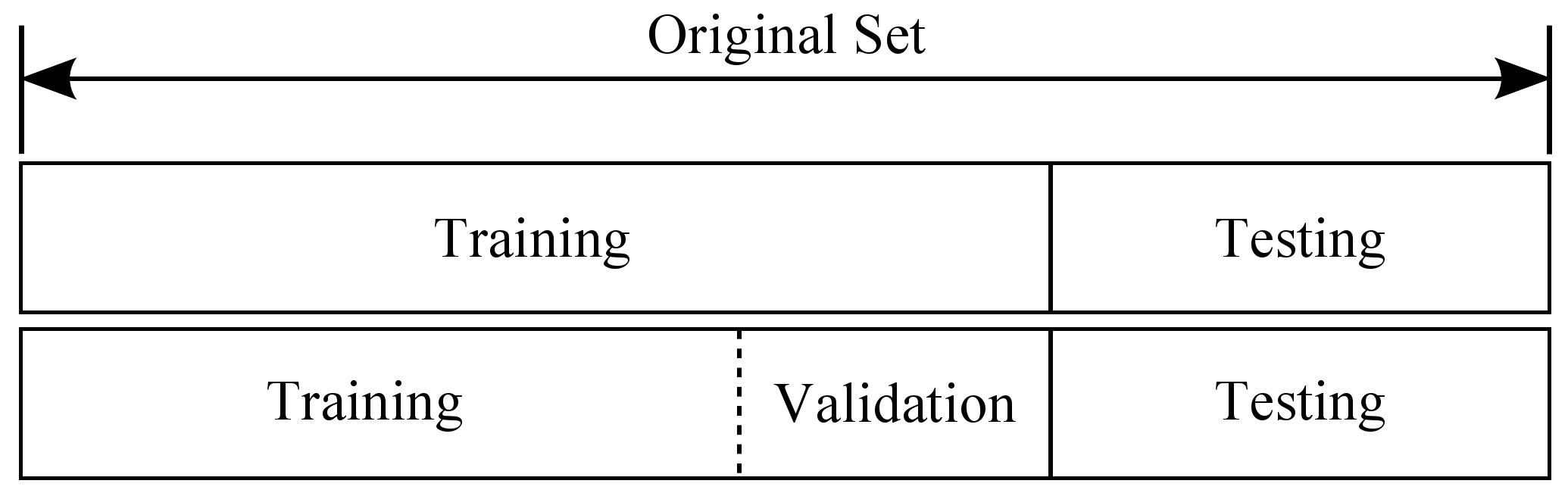
Ripley, B.D(1996)在他的经典专著Pattern Recognition and Neural Networks中给出了这三个词的定义。
- Training set: A set of examples used for learning, which is to fit the parameters [i.e., weights] of the classifier.
- Validation set: A set of examples used to tune the parameters [i.e., architecture, not weights] of a classifier, for example to choose the number of hidden units in a neural network.
- Test set: A set of examples used only to assess the performance [generalization] of a fully specified classifier.
训练集(Training set)
作用:估计模型
学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分类的方式,主要是用来训练模型的。
验证集(Cross ValidaDon set)
作用是当通过训练集训练出多个模型后,为了能找出效果最佳的模型,使用各个模型对验证集数据进行预测,并记录模型准确率。选出效果最佳的模型所对应的参数,即用来调整模型参数。如svn中的参数c和核函数等。
测试集(Test set)
检验最终选择最优的模型的性能如何,主要是测试训练好的模型的分辨能力(识别率等)。通过训练集和验证集得出最优模型后,使用测试集进行模型预测。用来衡量该最优模型的性能和分类能力。即可以把测试集当做从来不存在的数据集,当已经确定模型参数后,使用测试集进行模型性能评价。
为何需要划分
Ripley也谈到了这个问题:Why separate test and validation sets?
- The error rate estimate of the final model on validation data will be biased (smaller than the true error rate) since the validation set is used to select the final model.
- After assessing the final model with the test set, YOU MUST NOT tune the model any further.
简而言之,为了防止过度拟合。如果我们把所有数据都用来训练模型的话,建立的模型自然是最契合这些数据的,测试表现也好。但换了其它数据集测试这个模型效果可能就没那么好了。就好像你给班上同学做校服,大家穿着都合适你就觉得按这样做就对了,那给别的班同学穿呢?不合适的概率会高吧。总而言之训练集和测试集不相同的话,模型泛华结果才好。
实际应用中,一般只将数据集分成两类,即training set 和test set,大多数文章并不涉及validation set。
一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。

样本少的时候,上面的划分就不合适了。常用的是留少部分做测试集。然后对其余N个样本采用K折交叉验证法。就是将样本打乱,然后均匀分成K份,轮流选择其中K-1份训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和再做平均作为选择最优模型结构的依据。特别的K取N,就是留一法(leave one out)。下面介绍交叉验证的划分方法。
交叉验证的形式
- K折交叉验证 :初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
- Holdout 验证 :将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.。Hold-OutMethod相对于K-fold Cross Validation 又称Double cross-validation ,或相对K-CV称 2-fold cross-validation(2-CV)
- 留一验证 : 留一验证只使用原本样本中的一个样本来当做验证集, 而剩余的则留下来当做训练资料。 这个步骤一直持续到每个样本都被当做一次验证资料。 事实上,这等同于 K-fold 交叉验证是一样的,其中K为原本样本个数。 在某些情况下是存在有效率的演算法,如使用kernel regression 和Tikhonov regularization。
k 折交叉验证通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
- 第一步,不重复抽样将原始数据随机分为 k 份。
- 第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
- 第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。
- 在每个训练集上训练后得到一个模型,
- 用这个模型在相应的测试集上测试,计算并保存模型的评估指标,
- 第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
k 一般取 10,
数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。
数据量大的时候,k 可以设小一点。
当 k=m 即样本总数时,叫做 留一法(Leave one out cross validation),每次的测试集都只有一个样本,要进行 m 次训练和预测。
这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布。但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。一般在数据缺乏时使用。
总结:
Holdout 验证
方法:将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.。Hold-OutMethod相对于K-fold Cross Validation 又称Double cross-validation ,或相对K-CV称 2-fold cross-validation(2-CV)
一般来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。
- 优点:好处的处理简单,只需随机把原始数据分为两组即可
- 缺点:严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性.(主要原因是 训练集样本数太少,通常不足以代表母体样本的分布,导致 test 阶段辨识率容易出现明显落差。此外,2-CV 中一分为二的分子集方法的变异度大,往往无法达到「实验过程必须可以被复制」的要求。)
K-fold cross-validation
K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
- 优点:K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性.
- 缺点:K值选取上
留一验证
正如名称所建议, 留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料, 而剩余的则留下来当做训练资料。 这个步骤一直持续到每个样本都被当做一次验证资料。 事实上,这等同于 K-fold 交叉验证是一样的,其中K为原本样本个数。 在某些情况下是存在有效率的演算法,如使用kernel regression 和Tikhonov regularization。