Pandas之DataFrame
DataFrame是一种由列向量和行向量组成的数据结构,它类似于电子数据表、数据库表格。
DataFrame的竖行称之为 column,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 column 和 index 来确定一个元素的位置,可以理解为一个二维数组。(有人把 DataFrame 翻译为“数据框”,是不是还可以称之为“筐”呢?向里面装数据嘛。)
DataFrame是一个类似于表格的数据类型,如图: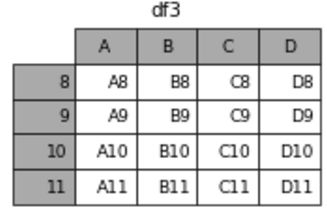
有这样一些参数:
data (方框内的数据): numpy ndarray (structured or homogeneous), dict, or DataFrame
index(行索引索引) : Index or array-like,如图中的8,9,9,10,11
columns (列索引): Index or array-like,如图中的A,B,C,D
dtype(data的数据类型) : dtype, default None
DataFrame统一的创建形式为:pd.DataFrame(data,columns=,index=)其中columns为列的索引,index为行的索引。index或者columns如果不进行设置则默认为0开始的整数,也是行的绝对位置,不会被覆盖;而通过外部数据(比如打开文件)创建DataFrame的话需要注意列名匹配的问题,给columns赋的值如果和数据来源当中列名不一样的话,对应的列下面会出现NAN。还有个常用参数为orient,默认为空,如果赋值’index’则将输入Series的index值作为DataFrame的columns。
Data的创建形式有以下几种:
一维数据类型进行创建:通过传递一维数据类型的形式创建。
二维数组创建:pd.DataFrame(二维数组,columns = ,index=);
外部输入就是读取文件等手段,如csv、excel等文件。概括来说就是先读取一个文件对象(pd.read_xxx,xxx是对应的文件类型,常用有csv、excel、table等)的对象,然后再通过该对象创建DataFrame,但要注意columns列名的命名。
一维数据类型创建
一维数据类型主要有:一维ndarray、列表、字典、Series等。首先是字典和Series类型创建DataFrame:
一个是将字典或者Series组合成列表进行创建:
import pandas as pd
a= {'a':1,'b':2}
b = pd.Series([1,2,3],index=list('abc'))
pd.DataFrame([a,b],columns = list('abcd'))
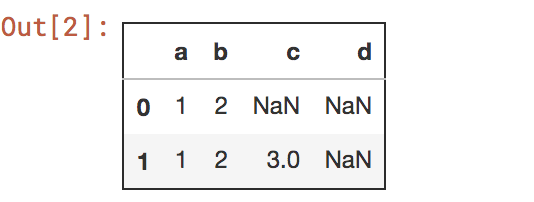
另一个是将两者放入字典里面创建:
import pandas as pd
a= {'a':1,'b':2}
b = pd.Series([1,2,3],index=list('abc'))
print('a:')
print(a)
print('\nb:')
print(b)
data = {'one':a,'two':b}
print('\ndata:')
print(data)
pd.DataFrame(data,columns = ['one','two','a','d'])

通过上面的例子发现,用一维数据结构来创建dataframe感觉很别扭,在结构的理解上很费劲,其实主要的原因是因为dataframe这种结构比较灵活导致的,如果语法更加的严格,明确指定data,colunm,index是不会导致理解上的困难。
下面的示例还是使用字典列表和嵌套字典来演示,但是理解上就比较轻松,
dic2 = {'a':[1,2,3,4],'b':[5,6,7,8],
'c':[9,10,11,12],'d':[13,14,15,16]}
dic2
type(dic2)
df2 = pd.DataFrame(dic2)
print(df2)
type(df2)
dic3 = {'one':{'a':1,'b':2,'c':3,'d':4},
'two':{'a':5,'b':6,'c':7,'d':8},
'three':{'a':9,'b':10,'c':11,'d':12}}
dic3
type(dic3)
df3 = pd.DataFrame(dic3)
print(df3)
type(df3)
输出:
a b c d
0 1 5 9 13
1 2 6 10 14
2 3 7 11 15
3 4 8 12 16
one three two
a 1 9 5
b 2 10 6
c 3 11 7
d 4 12 8
Out[14]:
pandas.core.frame.DataFrame
参数是dict,每个 dict 的 value 会被转化成一个 Series:
df2 = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
print(df2)
输出:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
总结:通过上述的例子,可以总结一种情况,默认情况下使用字典来创建dataframe这种二维数据结构,字典的key会充当column,但是如果字典是嵌套的话,嵌套字典的列会充当index的。
通过二维数组创建数据框
import numpy as np
import pandas as pd
arr2 = np.array(np.arange(12)).reshape(4,3)
arr2
type(arr2)
df1 = pd.DataFrame(arr2)
print(df1)
type(df1)
输出:
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
Out[18]:
pandas.core.frame.DataFrame
标准的dataframe创建,下面的这个例子很好体现出用data、column、index来创建dataframe:
dates = pd.date_range('20130101', periods=6)
print(dates)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print('\n',df)
输出:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
A B C D
2013-01-01 0.632776 0.512769 -0.548607 -1.455912
2013-01-02 -0.640468 0.142681 -0.890662 1.550619
2013-01-03 1.026986 0.945596 0.814094 0.876710
2013-01-04 0.241401 1.477270 1.979373 -0.698561
2013-01-05 0.014577 -2.107954 -0.216417 -0.159051
2013-01-06 1.836602 0.415864 -0.330007 0.246363
通过文件读取创建
文件处理是Pandas的重要特性,将在后续章节中重点介绍。